Sora: OpenAI’s Cutting-Edge AI Model Unveiled
OpenAI Introduces Sora for Text-to-Video Conversion

Earlier today, Google unveiled version 1.5 of Gemini. It targeted developers and enterprise users. In a bid to match this, OpenAI, one of Google’s major competitors, also made a significant AI announcement today. However, OpenAI’s announcement revolves around the introduction of a new text-to-video AI model.
OpenAI recently introduced a groundbreaking text-to-video generative AI model named Sora in a blog post and on various social media platforms. Alongside the announcement, they shared clips generated by the software, showcasing a diverse range of content, from a vibrant Chinese Lunar New Year celebration to an animated scene featuring a monster captivated by a red candle.
OpenAI has announced that Sora is currently being deployed for assessment by red teamers, who specialize in evaluating critical areas for potential harms or risks. These red teamers encompass experts in fields such as misinformation, hateful content, and bias. Furthermore, Sora will undergo safety evaluations akin to those established for DALL·E 3. Additionally, OpenAI is actively developing tools designed to identify videos generated by Sora, enhancing transparency and accountability in AI-generated content.
Google Rebrands Bard with Gemini AI
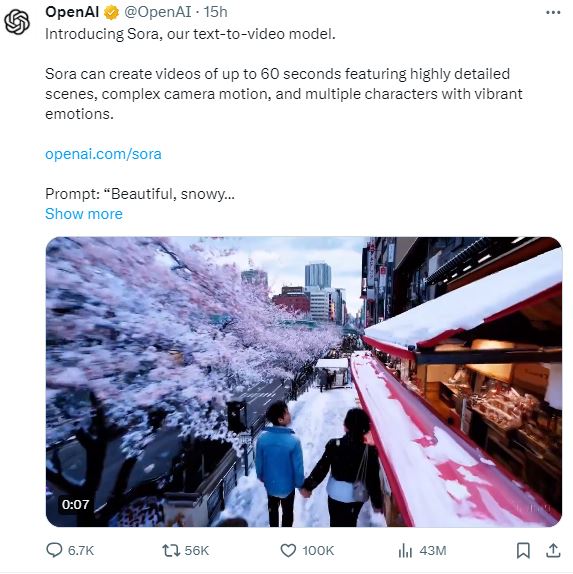
While competitors like Pika and Stability AI have entered the AI video generation arena ahead of OpenAI, Sora boasts several distinctive features. Firstly, Sora can generate videos lasting up to 60 seconds, a significant improvement over competitors’ capabilities, which typically produce only about four seconds of content. Moreover, Sora excels in delivering sharpness, high resolution, and accuracy in depicting the surrounding environment—a notable advantage that sets it apart from others in the field.
The current model has weaknesses. It may struggle with accurately simulating the physics of a complex scene, and may not understand specific instances of cause and effect. For example, a person might take a bite out of a cookie, but afterward, the cookie may not have a bite mark. The model may also confuse the spatial details of a prompt, for example, mixing up left and right, and may struggle with precise descriptions of events that take place over time, like following a specific camera trajectory, OpenAI states.
You can witness an example of this in the initial video showcased in the blog. The video portrays a woman strolling through Tokyo. Upon closer observation, you’ll notice occasional inconsistencies, such as the woman’s legs appearing to switch or stutter, her feet gliding unnaturally across the ground, and alterations in her outfit and hairstyle towards the conclusion of the clip.
Despite Sora not being accessible to the general public at the moment, CEO Sam Altman has been accepting prompts from users on X.
Stay tuned for further updates about Sora. Let us know in the comments section if you have anything to add to this article.
PTA Taxes Portal
Find PTA Taxes on All Phones on a Single Page using the PhoneWorld PTA Taxes Portal
Explore NowFollow us on Google News!





